Features
-Features-
Lexical Analysis – How to Measure the Lexical Diversity of your Text
What best describes you?
What is Lexical Diversity?
Lexical diversity is another key linguistic feature that we can analyse professionally using the Text Inspector tool.
This will help you understand the language use and complexity of the text in question. If you’re a second language learner, this could also help you to expand your vocabulary and improve your language skills.
As the name suggests, ‘lexical diversity’ is a measurement of how many different lexical words there are in a text.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey meaning in a text. They’re the words that you’d expect a child to use when first learning to speak. For example, ‘cat’ ‘play’ and ‘red’.
These are different from grammatical words that hold the text together and show relationships. These words include articles, pronouns, and conjunctions. For example ‘the’, ‘his’ and ‘or’.
What does Lexical Diversity Show?
Lexical diversity (LD) is considered to be an important indicator of how complex and difficult to read a text is. To illustrate what we mean, let’s imagine that you have two texts in front of you:
1) The first is a text that keeps repeating the same few words again and again. For example, ‘manager’, ‘thinks’ and ‘finishes’.
2) The second is a text that avoids this kind of repetition and instead uses different vocabulary to convey the same ideas. For example, ‘manager, boss, chief, head, leader’, ‘thinks, deliberates, ponders, reflects’, and ‘finishes, completes, finalises’.
As you can no doubt see yourself, the first text would be much easier to read, whereas the second is likely to be more complex and challenging. You could also say that the second text has more ‘lexical diversity’ than the first.
However, the complexity of a text isn’t just about using a wide variety of vocabulary words. It also depends on other factors including how these lexical words are used.
How to use Text Inspector to Analyse the Lexical Diversity of Your Text
Text Inspector is perhaps the best place on the web to measure Lexical Diversity in your text.
Start by visiting the Start A New Analysis page and then either pasting your text into the search box or upload your document. You’ll be given a summary of the analysis.
By looking to the left of your screen, you’ll see a tab titled ‘Lexical Diversity’ which you can click for more information. We’ve included the table here of the typical ranges you can expect for different groups of people (native and second language learners) for easy reference.
It’s also a good idea to run the analysis several times and take an average of the score because Text Inspector measures lexical density by sampling different parts of your text randomly. This means that each time you run an analysis, you will get a slightly different figure for the same text!
Try it now! You can analyse short texts up to 250 words for free.
Measure Lexical Diversity
Lexical diversity is another key linguistic feature that we can analyse professionally using the Text Inspector tool.
This will help you understand the language use and complexity of the text in question. If you’re a second language learner, this could also help you to expand your vocabulary and improve your language skills.
What is Lexical Diversity?
As the name suggests, ‘lexical diversity’ is a measurement of how many different lexical words there are in a text.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey meaning in a text. They’re the words that you’d expect a child to use when first learning to speak. For example, ‘cat’ ‘play’ and ‘red’.
These are different from grammatical words that hold the text together and show relationships. These words include articles, pronouns, and conjunctions. For example ‘the’, ‘his’ and ‘or’.
What Does Lexical Diversity Show?
Lexical diversity (LD) is considered to be an important indicator of how complex and difficult to read a text is.
To illustrate what we mean, let’s imagine that you have two texts in front of you:
1. The first is a text that keeps repeating the same few words again and again. For example, ‘manager’, ‘thinks’ and ‘finishes’.
2. The second is a text that avoids this kind of repetition and instead uses different vocabulary to convey the same ideas. For example, ‘manager, boss, chief, head, leader’, ‘thinks, deliberates, ponders, reflects’, and ‘finishes, completes, finalises’.
As you can no doubt see yourself, the first text would be much easier to read, whereas the second is likely to be more complex and challenging. You could also say that the second text has more ‘lexical diversity’ than the first.
However, lexical diversity isn’t the only indicator of how complex a text might be or the skill of the language user.
In their 2004 paper entitled “Developmental Trends in Lexical Diversity”, Duran et al. explained:
“…lexical diversity is about more than vocabulary range. Alternative terms, ‘flexibility’, ‘vocabulary richness’, ‘verbal creativity’, or ‘lexical range and balance’ indicate that it has to do with how vocabulary is deployed as well as how large the vocabulary might be.”
In other words, the complexity of a text isn’t just about using a wide variety of vocabulary words. It also depends on other factors including how these lexical words are used.
What does Lexical Diversity tell us About the Language user?
Lexical diversity can tell us a great deal about the language user including their skill with the language (as both native and second language learner) and also give clues as to their age.
In their book, ‘Lexical Diversity and Language Development’ (2004), Duran et al. offer a useful scale as follows:
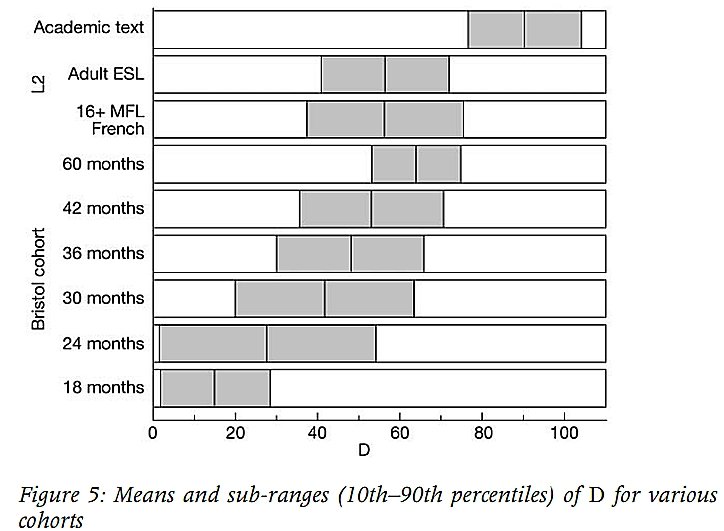
As you can see from the scale above, an adult second language learner would typically have a diversity measure of somewhere between 40-70. An adult native speaker who is writing an academic text who would typically have a measure of between 80-105.
How to use Text Inspector to Analyse the Lexical Diversity of Your Text
Text Inspector is perhaps the best place on the web to measure Lexical Diversity in your text.
Start by visiting the Start A New Analysis page and then either pasting your text into the search box or upload your document. You’ll be given a summary of the analysis.
By looking to the left of your screen, you’ll see a tab titled ‘Lexical Diversity’ which you can click for more information. We’ve included the table here of the typical ranges you can expect for different groups of people (native and second-language learners) for easy reference.
It’s also a good idea to run the analysis several times and take an average of the score because Text Inspector measures lexical density by sampling different parts of your text randomly. This means that each time you run an analysis, you will get a slightly different figure for the same text!
Why we use MTLD and voc-d at Text Inspector
At Text Inspector, we use two measures which seem to be the most reliable. These are:
1). MTLD (Measure of Textual Lexical Diversity)
2). vocd-D
By using these together, we can get a clearer idea of the text as a whole and avoid drawing false conclusions.
This is a point of view shared by linguists Dr Philip McCarthy and Scott Jarvis in their paper ‘MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment’ (2010):
“We conclude by advising researchers to consider using MTLD, vocd-D (or HD-D), and Maas in their studies, rather than any single index, noting that lexical diversity can be assessed in many ways and each approach may be informative as to the construct under investigation.” (McCarthy and Jarvis 2010: Abstract, p381)
They note, however, that it still retains an element of sensitivity to text length.
See also this interesting discussion on “Evaluating the Comparability of Two Measures of Lexical Diversity” by Fredrik deBoer. He also makes the point that: “VOCD-D is still affected by text length, and its developers caution that outside of an ideal range of perhaps 100-500 words, the figure is less reliable.” (np)
Source, Acknowledgements, and Technical Information
Further Reading
Another useful online tool you could look at is Paul Meara’s tool for measuring D at http://www.lognostics.co.uk/tools/D_Tools/D_Tools.htm.In the technical descriptors are the following notes, which should be borne in mind:
NOTE however, that results from Paul Meara’s tool are not directly comparable with results from Text Inspector, as his tool measures on a scale from 0-100, whereas TI measures on a scale from 0-200.
References:
– Duran, P, D. Malvern, B. Richards, N. Chipere (2004) “Developmental Trends in Lexical Diversity” Applied Linguistics OUP 25/2: 220-242
– McCarthy, P. M., & Jarvis, S. (2007) ‘vocd: A theoretical and empirical evaluation’. Language Testing, 24, 459-488
– McCarthy, P.M., & Jarvis, S. (2010). MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment, Behavior Research Methods, 42(2): 381-392
What is Lexical Diversity?
As the name suggests, ‘lexical diversity’ is a measurement of how many different lexical words there are in a text.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey meaning in a text. They’re the words that you’d expect a child to use when first learning to speak. For example, ‘cat’ ‘play’ and ‘red’.
These are different from grammatical words that hold the text together and show relationships. These words include articles, pronouns, and conjunctions. For example ‘the’, ‘his’ and ‘or’.
What is Lexical Diversity?
As the name suggests, ‘lexical diversity’ is a measurement of how many different lexical words there are in a text.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey meaning in a text. They’re the words that you’d expect a child to use when first learning to speak. For example, ‘cat’ ‘play’ and ‘red’.
These are different from grammatical words that hold the text together and show relationships. These words include articles, pronouns, and conjunctions. For example ‘the’, ‘his’ and ‘or’.