-Blog-

Lexical diversity and lexical density are two ways in which we can analyse a text and understand more about its linguistics features.
By understanding this information, we can also understand the CEFR level of the text and make better informed decisions when planning the language materials we’ll use with our ESOL students. It also allows us to gain a better insight as to the overall language skill of the individual without formal testing and can help us to become better teachers and learners.
But what exactly is lexical diversity and how is it measured? Is it different to lexical density and if so, why?
Today we’ll be answering these questions for you so you can get more out of using the Text Inspector tool.
What is lexical diversity?
Lexical diversity is a measure of how many different words appear in a text and it can be calculated in several different ways.
We might consider the total number of words in the text, or consider only the number of clauses in each sentence, or we might focus on the lexical words.
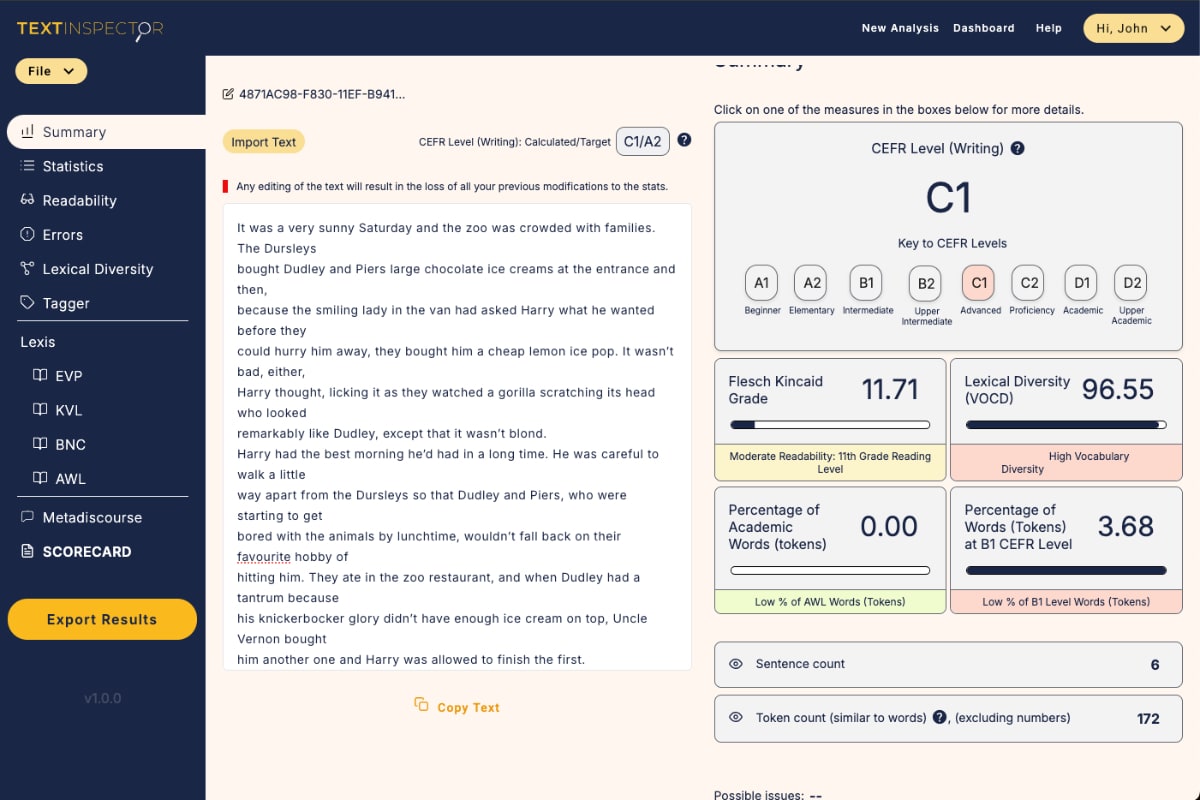
At Text Inspector, we consider two of these; token-type ratios (TTR) and lexical diversity (LD).
Token-type ratios
Traditionally, linguistics have used something called a token-type ratio to calculate linguistic diversity.
This takes the number of ‘types’ (different words) and divides them by the tokens (total number of words in the text).
Although the token-type ratio can be an extremely useful way of analysing a text to calculate its lexical diversity, this approach has received some criticism over recent years.
This is because it doesn’t work as effectively when dealing with longer texts. The longer the text, the more likely we are to repeat function words and the less likely we are to encounter unique words.

Function words or grammatical words as they’re also known mainly hold the text together, instead of conveying meaning. These include words like pronouns, articles, conjunctions and auxiliary verbs.
[See the discussion by Peter Robinson in his 2011 paper ‘Second language task complexity, the Cognition Hypothesis, language learning, and performance’.]
Despite its limitations, the token-type ratio can still be useful when analysing texts, which is why we do include it in our Statistics and Readability scores.
Lexical diversity
Here at Text Inspector, we use an alternative method of calculating lexical diversity where we focus on the lexical words used in the text. We use a specific sampling methodology in our analysis that helps us compare texts of different lengths effectively.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey the meaning of a text. For example, in the sentence, “I just spilled coffee over my laptop so I’ll have to buy a brand new one”, the underlined words are the lexical words.
We take these lexical words and divide them by the total of words in the text to achieve a score we call Lexical Diversity, or LD.
Why does lexical diversity matter?
Lexical diversity can help us understand how complex a text is and therefore how difficult it is for both native and non-native speakers to read as well as the potential language skill of the person who created it.
Texts that are lexically diverse use a wide range of vocabulary, avoid repetition, use precise language and tend to use synonyms to express ideas.
For example, imagine that you’re reading the story of someone receiving terrible news.
A lexically diverse text is likely to describe the way the person cries using a variety of synonyms such as ‘weep’, ‘shed tears’, ‘sob’, ‘wail’, ‘wimper’, ‘bawl’, and so on. These words are more specific than if the person was to just use the vocabulary word ‘cry’ as they can express a range of emotions.
When we analyse lexical diversity in this way, we can also gain a great deal of information about the language user including their age, their level of education and often whether they’re a native speaker of English or learning English as a second language.
When it comes to language learning, we can also use this information to decide whether a text is suitable for a certain level of language learner, or to assess their ability to create written texts in this language.
After all, students who are at a higher CEFR level such as those at B2+ are more likely to be able to understand and create more lexically diverse texts than those who are just starting out. They quite literally know and understand more words and are more skilled with the language as a whole
To further illustrate these ideas, here’s an interesting scale which shows how linguistic diversity is related to the factors we’ve mentioned above such as age, education and language learning:
From ‘Lexical Diversity and Language Development’ (2004), Duran et al.
What are the limitations of using lexical diversity to assess language complexity?
Although analysing lexical diversity can be a highly effective way of understanding language use, it’s not the only factor that affects text complexity.
Naturally, there are other things such as language creativity and sentence structure (syntax) that also play an important part.
This is an idea supported by Pilar Duran and colleagues in their 2004 paper, ‘Developmental Trends in Lexical Diversity’;
“…lexical diversity is about more than vocabulary range. Alternative terms, ‘flexibility’, ‘vocabulary richness’, ‘verbal creativity’, or ‘lexical range and balance’ indicate that it has to do with how vocabulary is deployed as well as how large the vocabulary might be.”
However, these limitations can be largely overcome by taking a wider look at language as a whole, and using the lexical diversity analysis alongside other analyses such as vocabulary use, number of syllables and readability as we do here at Text Inspector.
What is lexical density?
Lexical density is often mentioned alongside lexical diversity as a way of analysing and understanding language.
It’s a calculation that takes the number of lexical words and divides them by the total number of words in order to analyse what proportion of the text contains lexical words.
Does lexical density matter?
Analysing lexical density can be a useful way to better understand a text because it can help explain its complexity and therefore whether it is suitable for certain language levels.
For example, more complex texts such as university textbooks tend to have a greater percentage of lexical words because the noun phrases they contain tend to be more complex in order to express a more specific meaning. This, naturally, will be more challenging to both native speakers and language learners alike.
However, as Vinh To and colleagues at the University of Tasmania discovered in the study ‘Lexical Density and Readability: A Case Study of English Textbooks’; there was an…”absence of convincing proof about any strong link between lexical density and readability, between lexical density and English reading comprehension text levels, as well as these text levels and their overall readability”.
This is one of the reasons why we don’t currently calculate lexical density in the Text Inspector analyses and instead focus on metrics such as lexical diversity instead. Having said that, we understand that it can be useful which is why we’re currently looking into how we can incorporate this into the tool in the future.
What if I want to calculate lexical density using Text Inspector?
Even though we don’t currently include data on lexical density in the calculations, you may be able to calculate it yourself after analysing a text.
If you are a subscriber start by exporting your results as a CSV or Excel file using the ‘export detailed analysis’ button on the Tagger tool.
The data in these files will be quite detailed, but you can easily find the lexical words you want to include by looking for labels assigned by the tagger tool – such as VV for verbs.
You can then manipulate this data and calculate lexical density by taking the lexical words and dividing them by the total number of words.

How Text Inspector analyses lexical diversity?
At Text Inspector, we primarily use the lexical diversity (LD) calculation when investigating factors such as the complexity of a text, whether it’s suitable for certain levels of language learning and potentially grading a student’s work.
Because we use lexical diversity alongside other detailed analyses of your text such as token-type ratio, readability and syllable count, we can provide more accurate and useful analyses of any kind of written or spoken text than using any one method alone.
How lexically diverse is your text? Try Inspector free today.
Share
Related Posts
Announcing the New and Improved Text Inspector 2.0!
5 March, 2025
We’re thrilled to announce the upcoming launch of the new and improved Text Inspector! This […]
Read More -> Lexical Density vs Lexical Diversity: What’s the Difference?
24 June, 2022
Lexical diversity and lexical density are two ways in which we can analyse a text and […]
Read More ->
Donald Trump Tweet Analysis
24 June, 2022
Donald Trump’s Language Use on Twitter: What Does Our Analysis Say? With over 77 million […]
Read More ->